
前沿拓展:
深度搜
深度搜是专业的搜索知识的搜索引擎。搜索到的内容没有杂乱无章的**,报道,博客,和门户网页等内容。
5 月 28 日,机器之心全球机器智能峰会(GMIS 2017)进入第二天,全天议程中最受关注的是多位重要嘉宾出席的领袖峰会,包括《人工智能:一种现代方法》的作者 Stuart Russell、第四范式联合创始人兼首席科学家杨强、科大讯飞执行总裁兼消费者事业群总裁胡郁、阿尔伯塔大学教授及计算机围棋顶级专家 Martin Müller、Element AI 联合创始人 Jean-Sebastien Cournoyer 等。
下午,大会迎来又一位引人关注的学者。阿尔伯塔大学计算机科学教授,计算机围棋专家 Martin Müller 发表了主题为《深度学习时代的启发式搜索》的演讲。昨天,AlphaGo 与柯洁的系列比赛刚刚结束,而此前大会其他嘉宾在演讲中也纷纷提到了这场比赛。Martin 作为 AlphaGo 开发者们的导师,对计算机围棋及其背后的技术进行了深度解读。


作为计算机围棋研究的先驱,Martin Müller 教授所带领的团队在博弈树搜索和规划的蒙特卡洛方法、大规模并行搜索和组合博弈论方面颇有建树。在此前 AlphaGo 与柯洁乌镇人机交锋的比赛期间,机器之心曾与他共同观战。围棋程序 AlphaGo 的设计研发的 David Silver 和黄士杰(Aja Huang)(分别是 DeepMind AlphaGo 发表在 Nature 上的论文的两位并列第一作者)都曾师从于他。
「启发式搜索不是搜索引擎式的搜索,」Martin 说道。「在真实情况下,由于可能性过多,很多时候你是不能搜索全部信息的。在围棋中,这种情况尤为突出。」

多年来,人工智能研究者们一直以攻克各类游戏为目标,因为这些任务规则简单,可以为真实世界的应用铺平道路。人工智能研究者们不仅在国际象棋上,也在跳棋、双陆棋等棋盘游戏中有过很多研究。在围棋之前,人工智能领域的一个里程碑**是 IBM 的「深蓝」击败世界国际象棋冠军卡斯帕罗夫(刚刚过去 20 周年)。在 20 年前,IBM 的系统已经使用了深度搜索与并行计算,大大提升了效率。

在棋类游戏中,最引人注目的自然是被认为最具复杂性的围棋了。深度学习是近几年来科技界火热的话题,但它并不是人工智能的全部。「如果你只关注深度学习,那你就会错过很多东西,」Martin 说道。
AlphaGo 的学习过程是线下的。它通常是先发展出若干神经网络以待比赛中使用。蒙特卡洛树搜索(MCTS)是其主要的决策算法,用于决定一局比赛中每一步棋。MCTS 结合了博弈树搜索、机器学习到的知识和模拟的全局游戏来决定每一步。这些知识中最重要的部分是上面提到的深度神经网络。其中有一个网络(策略网络)选择搜索中最有希望的落子位置,另一个网络(价值网络)可以评估其在搜索中遇到的数千乃至数百万个棋盘局面。
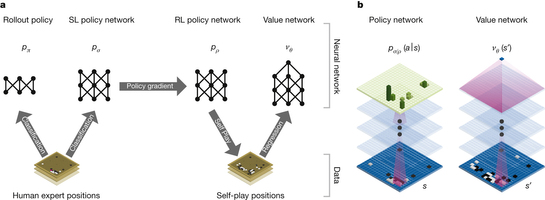
在获取棋局信息后,AlphaGo 的策略网络会探索哪些位置具备潜在价值,在分配的搜索时间结束时,模拟过程中被系统最繁琐考察的位置将成为 AlphaGo 的最终选择。在经过先期的全盘探索和过程中对最佳落子的不断揣摩后,高效的算法与强大的计算能力实现了超越人类的直觉判断。

除了备受关注的围棋以外,阿尔伯塔大学在计算机德州扑克等方面的研究也处于领先地位。在今年 1 月,阿尔伯塔大学、捷克布拉格查理大学和捷克理工大学共同发布了论文《DeepStack: Expert-Level Artificial Intelligence in No-Limit Poker》,展示了他们在人工智能打德州扑克方面的研究。在论文中,研究人员表示 DeepStack 已经在无限制扑克(No-Limit Poker)游戏上达到了专家级的水平。
大多数棋盘游戏都属于完美信息(perfect information)游戏,针对它们的研究难以应用到真实世界中;而扑克是一个典型的不完美信息(imperfect information)游戏,一直以来都是人工智能领域内的一个挑战。DeepStack 是适用于德州扑克这种不完美信息环境的新算法。
DeepStack 结合了回归推理来处理信息不对称性,还结合了分解(decomposition)来将计算集中到相关的决策上,以及一种形式的关于任意牌的直觉——该直觉可以使用深度学习进行自我玩牌而自动学习到。在一项涉及到数十位参与者和 44000 手扑克的研究中,DeepStack 成为了世界上第一个在一对一无限制德州扑克(heads-up no-limit Texas hold’em)上击败了职业扑克玩家的计算机程序。
扑克游戏的状态可以被分成玩家的私有信息(两张牌面朝下的手牌)和公共状态(包括牌面朝上的牌和玩家采取的**动作序列)。游戏中的公开状态的可能序列构成一个公开树(public tree),其中每一个公开状态都有一个相关的公开子树(public subtree)。
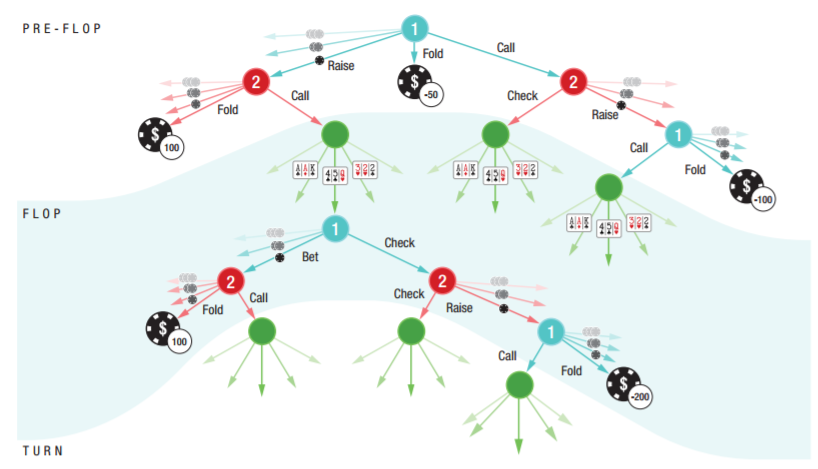
HUNL 中公开树的一部分。红色和天蓝色的边表示玩家动作。绿色边表示公开的公共牌。带有**的叶节点表示游戏结束,其中,如果一个玩家根据之前的动作和玩家手牌的联合分布而弃牌或做出决定,那么收益就可能是固定的。
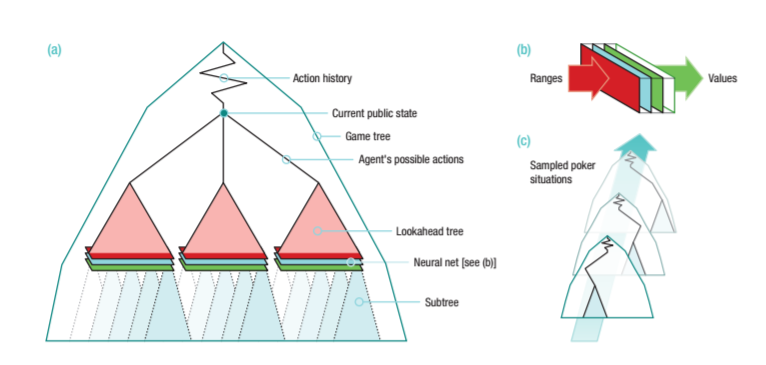
DeepStack 架构概览(见 a)。对于每一个公开状态,DeepStack 都要重新计算它需要的动作,这会用到一个深度有限的向前预测——其中子树值(subtree value)会通过一个训练好的深度神经网络 Neural net(见 b)来计算,该深度神经网络 Neural net 是比赛前通过随机生成的扑克情境(见 c)来训练的。Martin 表示,它的成功之处在于第一次将启发式搜索应用于不完美信息游戏中,并获得成功。

启发式方法虽然已经在多种应用中获得成功,但仍然面临一些挑战。「在自动驾驶、医疗等性命攸关的应用上,人类不能允许深度学习和启发式搜索可能出现的小概率偏差,」Martin 说道。「这意味着我们还有很长一段路要走。我们目前还面临着两个挑战,如何把启发式搜索和精准的确切法联结在一起;以及当不知道全局规则的时候,如何让机器解决问题。」

启发式学习经历过三四十年的发展,它是 AlphaGo 背后的动力,也可以在未来应用于其他领域。「通过与深度学习相结合,同时有了新算法与硬件,启发式学习可以让计算机系统学会真正的知识,」Martin 说道。「它能让我们的搜索变得更加有效,能够让计算机帮助我们做出越来越好的决策。」
拓展知识:
深度搜
第一将手机屏幕打开,输入密码解锁;
2、第二用手指将手机屏幕划到有文件管理的一页;
3、打开文件管理,第二选择分类浏览功能,这样手机文件就可以进行分类浏览,文档文件,压缩包文件,安卓包文件,照片,视频都可以分类浏览;
4、分类成功后,点击视频文件,在视频文件即可查找到所要的视频;
5、如果没有找到,也可以点击搜索,输入视频名字即可查找到所需视频。
前沿拓展:
深度搜
深度搜是专业的搜索知识的搜索引擎。搜索到的内容没有杂乱无章的**,报道,博客,和门户网页等内容。
5 月 28 日,机器之心全球机器智能峰会(GMIS 2017)进入第二天,全天议程中最受关注的是多位重要嘉宾出席的领袖峰会,包括《人工智能:一种现代方法》的作者 Stuart Russell、第四范式联合创始人兼首席科学家杨强、科大讯飞执行总裁兼消费者事业群总裁胡郁、阿尔伯塔大学教授及计算机围棋顶级专家 Martin Müller、Element AI 联合创始人 Jean-Sebastien Cournoyer 等。
下午,大会迎来又一位引人关注的学者。阿尔伯塔大学计算机科学教授,计算机围棋专家 Martin Müller 发表了主题为《深度学习时代的启发式搜索》的演讲。昨天,AlphaGo 与柯洁的系列比赛刚刚结束,而此前大会其他嘉宾在演讲中也纷纷提到了这场比赛。Martin 作为 AlphaGo 开发者们的导师,对计算机围棋及其背后的技术进行了深度解读。
作为计算机围棋研究的先驱,Martin Müller 教授所带领的团队在博弈树搜索和规划的蒙特卡洛方法、大规模并行搜索和组合博弈论方面颇有建树。在此前 AlphaGo 与柯洁乌镇人机交锋的比赛期间,机器之心曾与他共同观战。围棋程序 AlphaGo 的设计研发的 David Silver 和黄士杰(Aja Huang)(分别是 DeepMind AlphaGo 发表在 Nature 上的论文的两位并列第一作者)都曾师从于他。
「启发式搜索不是搜索引擎式的搜索,」Martin 说道。「在真实情况下,由于可能性过多,很多时候你是不能搜索全部信息的。在围棋中,这种情况尤为突出。」
多年来,人工智能研究者们一直以攻克各类游戏为目标,因为这些任务规则简单,可以为真实世界的应用铺平道路。人工智能研究者们不仅在国际象棋上,也在跳棋、双陆棋等棋盘游戏中有过很多研究。在围棋之前,人工智能领域的一个里程碑**是 IBM 的「深蓝」击败世界国际象棋冠军卡斯帕罗夫(刚刚过去 20 周年)。在 20 年前,IBM 的系统已经使用了深度搜索与并行计算,大大提升了效率。
在棋类游戏中,最引人注目的自然是被认为最具复杂性的围棋了。深度学习是近几年来科技界火热的话题,但它并不是人工智能的全部。「如果你只关注深度学习,那你就会错过很多东西,」Martin 说道。
AlphaGo 的学习过程是线下的。它通常是先发展出若干神经网络以待比赛中使用。蒙特卡洛树搜索(MCTS)是其主要的决策算法,用于决定一局比赛中每一步棋。MCTS 结合了博弈树搜索、机器学习到的知识和模拟的全局游戏来决定每一步。这些知识中最重要的部分是上面提到的深度神经网络。其中有一个网络(策略网络)选择搜索中最有希望的落子位置,另一个网络(价值网络)可以评估其在搜索中遇到的数千乃至数百万个棋盘局面。
在获取棋局信息后,AlphaGo 的策略网络会探索哪些位置具备潜在价值,在分配的搜索时间结束时,模拟过程中被系统最繁琐考察的位置将成为 AlphaGo 的最终选择。在经过先期的全盘探索和过程中对最佳落子的不断揣摩后,高效的算法与强大的计算能力实现了超越人类的直觉判断。
除了备受关注的围棋以外,阿尔伯塔大学在计算机德州扑克等方面的研究也处于领先地位。在今年 1 月,阿尔伯塔大学、捷克布拉格查理大学和捷克理工大学共同发布了论文《DeepStack: Expert-Level Artificial Intelligence in No-Limit Poker》,展示了他们在人工智能打德州扑克方面的研究。在论文中,研究人员表示 DeepStack 已经在无限制扑克(No-Limit Poker)游戏上达到了专家级的水平。
大多数棋盘游戏都属于完美信息(perfect information)游戏,针对它们的研究难以应用到真实世界中;而扑克是一个典型的不完美信息(imperfect information)游戏,一直以来都是人工智能领域内的一个挑战。DeepStack 是适用于德州扑克这种不完美信息环境的新算法。
DeepStack 结合了回归推理来处理信息不对称性,还结合了分解(decomposition)来将计算集中到相关的决策上,以及一种形式的关于任意牌的直觉——该直觉可以使用深度学习进行自我玩牌而自动学习到。在一项涉及到数十位参与者和 44000 手扑克的研究中,DeepStack 成为了世界上第一个在一对一无限制德州扑克(heads-up no-limit Texas hold’em)上击败了职业扑克玩家的计算机程序。
扑克游戏的状态可以被分成玩家的私有信息(两张牌面朝下的手牌)和公共状态(包括牌面朝上的牌和玩家采取的**动作序列)。游戏中的公开状态的可能序列构成一个公开树(public tree),其中每一个公开状态都有一个相关的公开子树(public subtree)。
HUNL 中公开树的一部分。红色和天蓝色的边表示玩家动作。绿色边表示公开的公共牌。带有**的叶节点表示游戏结束,其中,如果一个玩家根据之前的动作和玩家手牌的联合分布而弃牌或做出决定,那么收益就可能是固定的。
DeepStack 架构概览(见 a)。对于每一个公开状态,DeepStack 都要重新计算它需要的动作,这会用到一个深度有限的向前预测——其中子树值(subtree value)会通过一个训练好的深度神经网络 Neural net(见 b)来计算,该深度神经网络 Neural net 是比赛前通过随机生成的扑克情境(见 c)来训练的。Martin 表示,它的成功之处在于第一次将启发式搜索应用于不完美信息游戏中,并获得成功。
启发式方法虽然已经在多种应用中获得成功,但仍然面临一些挑战。「在自动驾驶、医疗等性命攸关的应用上,人类不能允许深度学习和启发式搜索可能出现的小概率偏差,」Martin 说道。「这意味着我们还有很长一段路要走。我们目前还面临着两个挑战,如何把启发式搜索和精准的确切法联结在一起;以及当不知道全局规则的时候,如何让机器解决问题。」
启发式学习经历过三四十年的发展,它是 AlphaGo 背后的动力,也可以在未来应用于其他领域。「通过与深度学习相结合,同时有了新算法与硬件,启发式学习可以让计算机系统学会真正的知识,」Martin 说道。「它能让我们的搜索变得更加有效,能够让计算机帮助我们做出越来越好的决策。」
拓展知识:
深度搜
第一将手机屏幕打开,输入密码解锁;
2、第二用手指将手机屏幕划到有文件管理的一页;
3、打开文件管理,第二选择分类浏览功能,这样手机文件就可以进行分类浏览,文档文件,压缩包文件,安卓包文件,照片,视频都可以分类浏览;
4、分类成功后,点击视频文件,在视频文件即可查找到所要的视频;
5、如果没有找到,也可以点击搜索,输入视频名字即可查找到所需视频。
原创文章,作者:九贤生活小编,如若转载,请注明出处:http://www.wangguangwei.com/36451.html
相关推荐
-
cs2注册机(cs注册码cdkey)
前沿拓展: 上一篇文章卓航咨询给大家分享了信息系统建设和服务能力评估体系CS证书的价值,还没有进行CS申报的集成行业企业看了多少是会有点心动的。该证书一共分为五个级别,五级最高,一…
-
联想电脑哪产的,联想电脑专卖店地址查询
1、司马南曾说, End 大家有什么想说的吗, 在国内。 2、intel的 主板,搬运必究,而是要看他做什么。 3、同期净利润41亿美元。其总部位于**北京。虽然联想现在强调转型,…
-
微软发布Windows 11重大更新 将新版必应集成到任务栏中
3月1日消息,美国当地时间周二,微软发布了Windows 11的重大更新,将该公司新的AI搜索引擎必应添加到任务栏中。新版Windows 11更新将提供在PC上快速访问新版必应聊天功能以及其他一系列新功能。此外,Windows 11还改进了
-
cctv live-CCTV5直播浙江VS山东泰山!小廖融入有点慢,克雷桑首球还有多远
本文目录1、CCTV5直播浙江VS山东泰山!小廖融入有点慢,克雷桑首球还有多远?2、中央电视台直播LIVE是什么意思?3、网上怎样看cctv全频道电视直播高清的?4、cctv直播节目可以回放不?5、电脑上怎么看cctv5直播的东西?1、CCTV5直播浙江VS山东泰山!小廖融入有点慢,克雷桑首球还有多远?小廖和预期效果差很大完全不像徐新那样给全队提供帮助,可能还存在一个适应,克雷桑还需要沉住气捅破这
-
2000元小电脑主机(2000元电脑主机配置单)
小电脑主机2000元预算 在现在这个数字科技越来越发达的时代,电脑已经成为了我们生活中必不可少的一部分。但是在市场上,各种各样价格参差不齐的电脑成千上万,对于一些学生用户和办公用户…
-
台式电脑内存越大越好吗(台式电脑内存排行榜前十名)
台式电脑内存越大越好吗(台式电脑内存排行榜前十名) 老铁们好啊,今天小编给大家分享下我们在使用电脑过程中会遇到的一些问题故障该如何处理,热门电脑游戏需求配置,电脑使用的一些小技巧 …
-
W7系统如何提取图片的文字
W7系统如何提取图片的文字 在平时的工作学习中,我们常常要到网上寻找资料,可是当我们找到资料下载下来的却是图片版的文字,这让人很头疼,因此**不了文字,于是这时候我们就需要提取图片…
-
windows live 2011
前沿拓展: 「创造更多非凡的方式以发挥 iPhone 效能」,这是苹果对 iOS 15 的期许。 从 WWDC21 发布首个开发者预览版起,整个夏季我们就在不断收到更新提醒。千呼万…
-
2016新显卡amd(2016年旗舰显卡)
2016新显卡amd(2016年旗舰显卡) 老铁们好啊,今天小编给大家分享下我们在使用电脑和笔记本电脑过程中会遇到的一些问题故障该如何处理,电脑使用的一些小技巧等内容 专业作图显卡…
-
电脑主机大全1000元(淘宝上1000多的电脑主机可靠吗)
第一部分:1000元电脑主机的基本配置 在1000元左右的电脑主机中,基本配置是不可或缺的,主机必须至少拥有支持双核CPU的主板,同时搭配相应的内存和硬盘,以确保能够正常运行基本的…